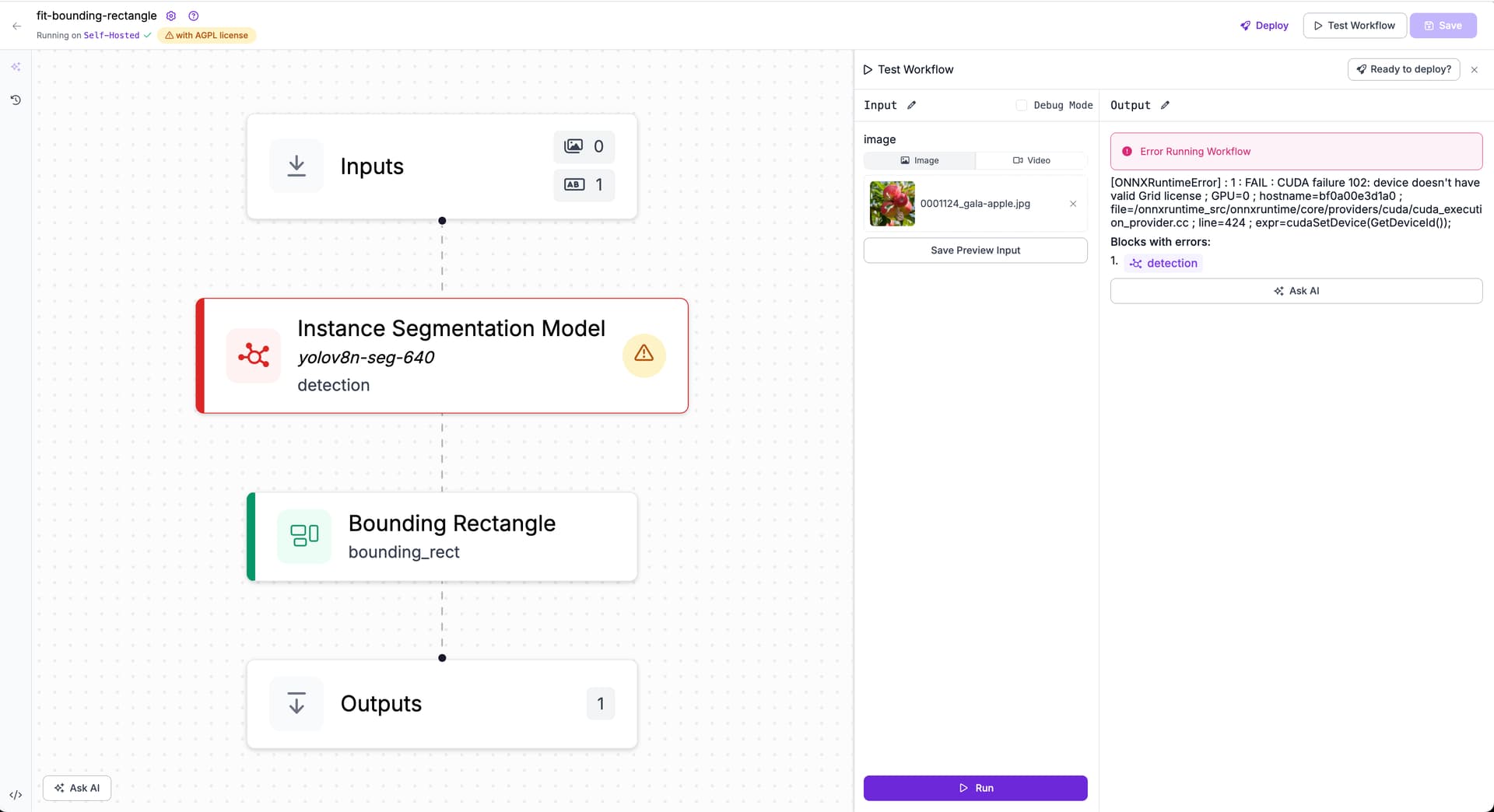
Ahoi Ford,
I made it work, it was a firewall issue internally from the NGINX Proxy to the roboflow container.
Have you seen this type of error?
[ONNXRuntimeError] : 1 : FAIL : CUDA failure 102: device doesn't have valid Grid license;
GPU=0;
hostname=bf0a00e3d1a0;
file=/onnxruntime_src/onnxruntime/core/providers/cuda/cuda_execution_provider.cc;
line=424;
expr=cudaSetDevice(GetDeviceId());
When I run the same workflow internally on the vm with localhost the workflow can be executed
Also I can see the connection attempt in the docker logs
INFO: 192.168.30.49:34420 - "OPTIONS / HTTP/1.1" 200 OK
INFO: 192.168.30.49:34426 - "HEAD / HTTP/1.1" 200 OK
INFO: 192.168.30.49:34442 - "OPTIONS /workflows/run HTTP/1.1" 200 OK
2025-07-28 20:12:46.369928887 [E:onnxruntime:Default, cuda_call.cc:123 CudaCall] CUDA failure 102: device doesn't have valid Grid license ; GPU=0 ; hostname=bf0a00e3d1a0 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/cuda_execution_provider.cc ; line=424 ; expr=cudaSetDevice(GetDeviceId());
{"event": "Execution of step $steps.detection encountered error.", "timestamp": "2025-07-28 20:12.46", "exception": {"type": "Fail", "message": "[ONNXRuntimeError] : 1 : FAIL : CUDA failure 102: device doesn't have valid Grid license ; GPU=0 ; hostname=bf0a00e3d1a0 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/cuda_execution_provider.cc ; line=424 ; expr=cudaSetDevice(GetDeviceId()); ", "stacktrace": [{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 130, "function": "safe_execute_step", "code": "run_step("},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 160, "function": "run_step", "code": "return run_simd_step("}, {"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 184, "function": "run_simd_step", "code": "return run_simd_step_in_batch_mode("},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 224, "function": "run_simd_step_in_batch_mode", "code": "outputs = step_instance.run(**step_input.parameters)"},
{"filename": "/app/inference/core/workflows/core_steps/models/roboflow/instance_segmentation/v1.py", "lineno": 211, "function": "run", "code": "return self.run_locally("},
{"filename": "/app/inference/core/workflows/core_steps/models/roboflow/instance_segmentation/v1.py", "lineno": 281, "function": "run_locally", "code": "predictions = self._model_manager.infer_from_request_sync("},
{"filename": "/app/inference/core/managers/decorators/fixed_size_cache.py", "lineno": 158, "function": "infer_from_request_sync", "code": "return super().infer_from_request_sync(model_id, request, **kwargs)"},
{"filename": "/app/inference/core/managers/decorators/base.py", "lineno": 106, "function": "infer_from_request_sync", "code": "return self.model_manager.infer_from_request_sync(model_id, request, **kwargs)"}, {"filename": "/app/inference/core/managers/active_learning.py", "lineno": 196, "function": "infer_from_request_sync", "code": "prediction = super().infer_from_request_sync("},
{"filename": "/app/inference/core/managers/active_learning.py", "lineno": 54, "function": "infer_from_request_sync", "code": "prediction = super().infer_from_request_sync("},
{"filename": "/app/inference/core/managers/base.py", "lineno": 231, "function": "infer_from_request_sync", "code": "rtn_val = self.model_infer_sync("},
{"filename": "/app/inference/core/managers/base.py", "lineno": 294, "function": "model_infer_sync", "code": "return self._models[model_id].infer_from_request(request)"},
{"filename": "/app/inference/core/models/base.py", "lineno": 134, "function": "infer_from_request", "code": "responses = self.infer(**request.dict(), return_image_dims=False)"},
{"filename": "/app/inference/core/models/instance_segmentation_base.py", "lineno": 97, "function": "infer", "code": "return super().infer("},
{"filename": "/app/inference/core/models/roboflow.py", "lineno": 771, "function": "infer", "code": "return super().infer(image, **kwargs)"},
{"filename": "/app/inference/usage_tracking/collector.py", "lineno": 693, "function": "sync_wrapper", "code": "res = func(*args, **kwargs)"},
{"filename": "/app/inference/core/models/base.py", "lineno": 29, "function": "infer", "code": "predicted_arrays = self.predict(preproc_image, **kwargs)"},
{"filename": "/app/inference/models/yolov8/yolov8_instance_segmentation.py", "lineno": 42, "function": "predict", "code": "predictions, protos = run_session_via_iobinding("},
{"filename": "/app/inference/core/utils/onnx.py", "lineno": 36, "function": "run_session_via_iobinding", "code": "predictions = session.run(None, {input_name: input_data})"},
{"filename": "/usr/local/lib/python3.10/dist-packages/onnxruntime/capi/onnxruntime_inference_collection.py", "lineno": 270, "function": "run", "code": "return self._sess.run(output_names, input_feed, run_options)"}]}, "filename": "core.py", "func_name": "safe_execute_step", "lineno": 142}
{"positional_args": ["StepExecutionError", "StepExecutionError(\"[ONNXRuntimeError] : 1 : FAIL : CUDA failure 102: device doesn't have valid Grid license ; GPU=0 ; hostname=bf0a00e3d1a0 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/cuda_execution_provider.cc ; line=424 ; expr=cudaSetDevice(GetDeviceId()); \")"], "event": "%s: %s", "request_id": "116752b975354d27bd951878d04753b0", "timestamp": "2025-07-28 20:12.46", "exception": {"type": "StepExecutionError", "message": "[ONNXRuntimeError] : 1 : FAIL : CUDA failure 102: device doesn't have valid Grid license ; GPU=0 ; hostname=bf0a00e3d1a0 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/cuda_execution_provider.cc ; line=424 ; expr=cudaSetDevice(GetDeviceId()); ", "stacktrace": [{"filename": "/app/inference/core/interfaces/http/http_api.py", "lineno": 283, "function": "wrapped_route", "code": "return await route(*args, **kwargs)"}, {"filename": "/app/inference/usage_tracking/collector.py", "lineno": 728, "function": "async_wrapper", "code": "res = await func(*args, **kwargs)"},
{"filename": "/app/inference/core/interfaces/http/http_api.py", "lineno": 1388, "function": "infer_from_workflow", "code": "return process_workflow_inference_request("},
{"filename": "/app/inference/core/interfaces/http/http_api.py", "lineno": 826, "function": "process_workflow_inference_request", "code": "workflow_results = execution_engine.run("},
{"filename": "/app/inference/core/workflows/execution_engine/core.py", "lineno": 73, "function": "run", "code": "return self._engine.run("},
{"filename": "/app/inference/core/workflows/execution_engine/v1/core.py", "lineno": 107, "function": "run", "code": "result = run_workflow("},
{"filename": "/app/inference/usage_tracking/collector.py", "lineno": 693, "function": "sync_wrapper", "code": "res = func(*args, **kwargs)"},
{"filename": "/app/inference/core/workflows/execution_engine/profiling/core.py", "lineno": 264, "function": "wrapper", "code": "return func(*args, **kwargs)"},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 62, "function": "run_workflow", "code": "execute_steps("},
{"filename": "/app/inference/core/workflows/execution_engine/profiling/core.py", "lineno": 264, "function": "wrapper", "code": "return func(*args, **kwargs)"},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 108, "function": "execute_steps", "code": "_ = run_steps_in_parallel("},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/utils.py", "lineno": 14, "function": "run_steps_in_parallel", "code": "return list(inner_executor.map(_run, steps))"},
{"filename": "/usr/lib/python3.10/concurrent/futures/_base.py", "lineno": 621, "function": "result_iterator", "code": "yield _result_or_cancel(fs.pop())"},
{"filename": "/usr/lib/python3.10/concurrent/futures/_base.py", "lineno": 319, "function": "_result_or_cancel", "code": "return fut.result(timeout)"},
{"filename": "/usr/lib/python3.10/concurrent/futures/_base.py", "lineno": 458, "function": "result", "code": "return self.__get_result()"},
{"filename": "/usr/lib/python3.10/concurrent/futures/_base.py", "lineno": 403, "function": "__get_result", "code": "raise self._exception"},
{"filename": "/usr/lib/python3.10/concurrent/futures/thread.py", "lineno": 58, "function": "run", "code": "result = self.fn(*self.args, **self.kwargs)"}, {"filename": "/app/inference/core/workflows/execution_engine/v1/executor/utils.py", "lineno": 37, "function": "_run", "code": "return fun()"},
{"filename": "/app/inference/core/workflows/execution_engine/profiling/core.py", "lineno": 264, "function": "wrapper", "code": "return func(*args, **kwargs)"},
{"filename": "/app/inference/core/workflows/execution_engine/v1/executor/core.py", "lineno": 144, "function": "safe_execute_step", "code": "raise StepExecutionError("}]}, "filename": "http_api.py", "func_name": "wrapped_route", "lineno": 475}
INFO: 192.168.30.49:34456 - "POST /workflows/run HTTP/1.1" 500 Internal Server Error
Is it that this is getting more and more complicated using an nVidia A100?
BR