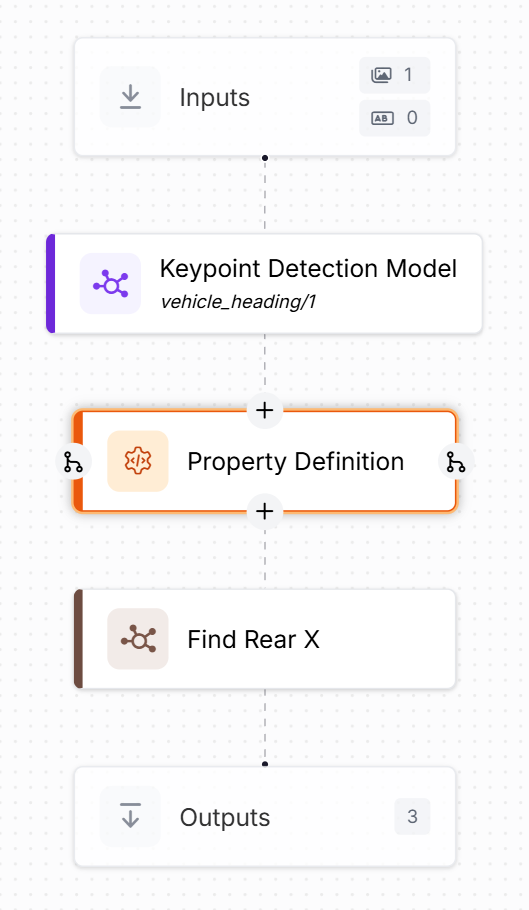
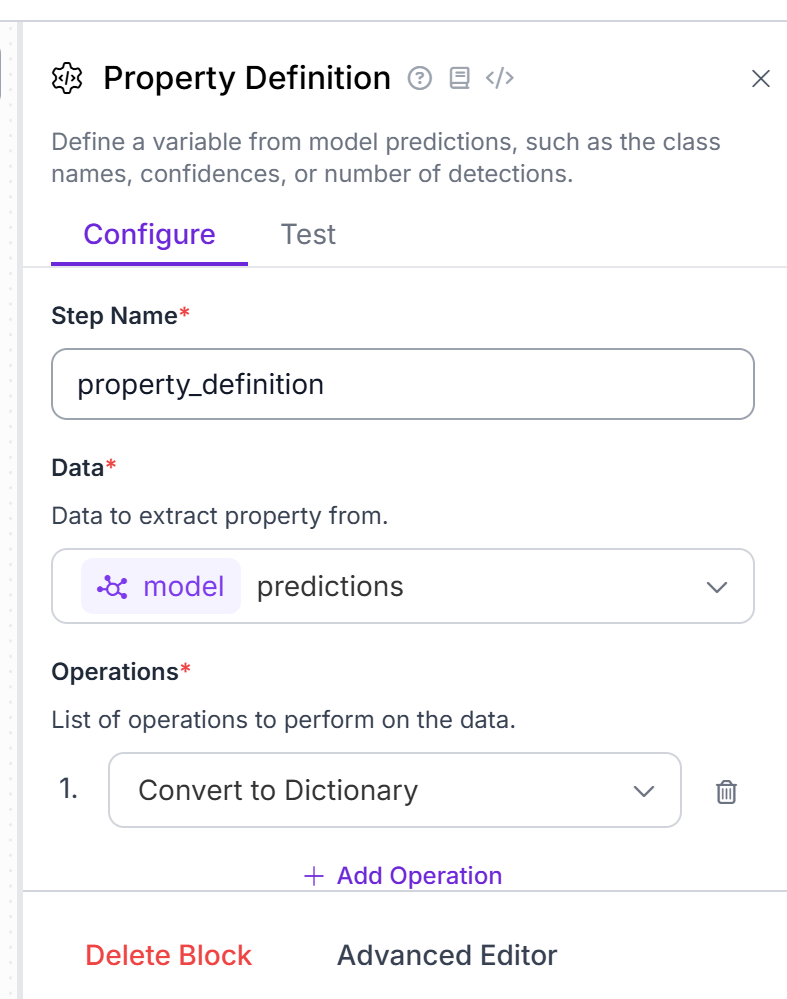
In developing our first custom python block, it took us some time to figure out how to reference attributes in the “face predictions” output from the “Gaze Detection” model, and this was due to the fact that the output as shown in the Data in / Data out portions of the blocks did not match the structure in the code.
Specifically, we found out eventually through some error messages and google searches, that the “face predictions” data was an sv.Detections object (Core - Supervision). However, in the Data in section (represented as the parameter “predictions”), it appears to be an array of dictionaries:
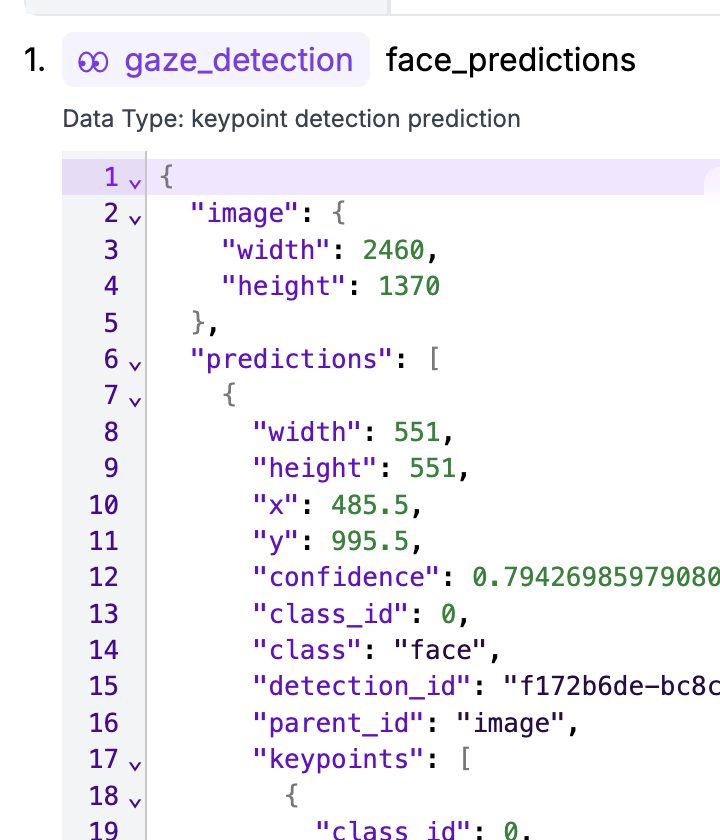
So, for example, getting the x & y of the bounding box of a prediction, from the info above, would appear to be done like this:
for p in predictions:
x1 = p["x"]
y1 = p["y"]
x2 = x1 + p["width"]
y2 = y1 + p["height"]
center_x = (x1 + x2) // 2
center_y = (y1 + y2) // 2
This fails, though, because sv.Predictions stores the rectangles in the array xyxy, and height & width in the dictionary data (as the array “height” and array “width”), meaning we do this:
for box in predictions.xyxy:
x1, y1, x2, y2 = map(int, box)
center_x = (x1 + x2) // 2
center_y = (y1 + y2) // 2
width = x2 - x1
height = y2 - y1
Is there someplace else we should be looking for the real structure of the data that is produced by upstream modules? I see from this example with gaze detection that if you invoke it via your own python, it returns the results as json. Was it incorrect to configure our block with a parameter called “predictions” of type “any” that is linked to the “face predictions” output of the gaze detection model? (cannot include a second screenshot due to account restrictions).
EDIT: please ignore the bits about the width & height above, those are from our own model, and don’t exist in the gaze detection example I’m using.